
With the launch of ChatGPT, the topic of artificial intelligence has become omnipresent. Whether it is in the context of medicine, research, finance, or e-learning, seemingly everybody prides themselves on incorporating artificial intelligence. Particularly, the use of and debate around ChatGPT has skyrocketed in this context. While most of us are aware of the fact that ChatGPT has vehement defenders as well as intense critics, we are often not aware of the mechanics behind ChatGPT as well as the possible repercussions of this program. Therefore, I would like to briefly sketch the mechanisms behind ChatGPT and artificial intelligence’s relationship to human neural modeling (as these models are frequently linked in articles on artificial neural networks), discuss some of its numerous applications, and also address potential challenges.
How can we use ChatGPT?
As one of the most effective language generators, ChatGPT can be used for a variety of tasks. For instance, I could have asked ChatGPT to help me write this text. After ChatGPT had provided me with an answer (see Figure 1), I could have modified it until I was satisfied with the results.
Probably, this would have been more efficient and faster than writing this entry without any help from ChatGPT. This efficiency is also why the program has become so popular and has (potential) applications beyond just helping with homework or writing emails. For instance, it can be used for automatically creating financial reports, analyzing medical data, generating code, and many more tasks (cf. Ray, 2023). After the release of ChatGPT, some research articles were even written entirely by this program to highlight its innovative nature and to evaluate it (cf. Kaplan-Marans & Khurgin, 2023).
How does ChatGPT work? – An overview
ChatGPT (i.e., Chat Generative Pre-Trained Transformer) is based on a large language model (LLM), which determines the following word or, more specifically, token in a sentence. For this, the item with the highest probability to occur in a given context is calculated based on a substantial data set consisting of a variety of texts that were used to train the model (Hashana et al., 2023).
In order to process language, ChatGPT employs natural language processing, which is illustrated in the following rudimentary diagram (Hashana et al., 2023, pp. 1002-1003).
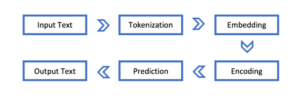
As shown in Figure 2, the input text is broken down into individual words and tokens. Furthermore, machine learning models require a numerical input, resulting in each token being assigned a numerical vector representation (i.e., embedding), which are subsequently combined to represent the entirety of the input (i.e., encoding). In the prediction phase, the model relies on numerous machine-learning techniques to predict the string of words used in the output. In the final step, it is necessary to convert the numerical representation of the output into natural language again.
For the aforementioned predictions, ChatGPT employs a variety of deep learning techniques, including:
- Recurrent Neural Networks (RNN): Neural networks, in general, are a layered network of artificial neurons (i.e., network nodes with the ability to process input and generate output), which are interconnected. These neurons are activated based on specific activation functions and are connected to other neurons with weights, demonstrating the significance of the individual connections (Tucci, 2018). RNNs are a particularly good option for text processing due to their capability to capture information from previous inputs (Hashana et al., 2023, p. 1002).
- Transformer architecture and Language Modeling: By focusing on certain aspects of the input and producing the following word of a sentence based on the previous words, these models are employed to generate more coherent output (Hashana et al., 2023, p. 1002; Kung et al., 2023).
- Generative pre-training: While various machine learning models use previously annotated data to train the program, ChatGPT also incorporates generative pre-training based on unsupervised learning for the pre-training phase (cf. Qadir, 2022; Hashana et al., 2023, p. 1002).
Artificial neural networks and the human neural network – can they even be compared?
One aspect that is often suggested in the context of neural networks, in general, is that they are modeled after the relationship of neurons in a human brain. However, in how far is this comparison adequate?
As with many highly debated questions, the answer probably depends on the perspective you view it from. Many programmers, for instance, would proudly state that the neural networks we have today are as close to human neural networks as they ever were and that the human neural network is their model. However, from a biomedical and physiological perspective, this statement does not really hold true, as shown by the following two basic features of human neural networks (F. Rattay, personal communication, June, 2023).
- The biomolecular structure of a neuron, including potassium and sodium channels, cannot be incorporated.
- The complexity of an action potential (i.e., firing of the neuron) itself is not reflected. This action potential includes de-, re-, and hyperpolarization, as well as the refractory period responsible for the fact that a neuron needs a short period to “rest” before it can fire again. As this is based on biochemical mechanisms and would not be beneficial in artificial neural networks, developers disregard it.
Thus, simply the firing of the basic unit in these systems cannot be adequately compared, and there would be too many similar discrepancies between the systems to address here. However, it should also be considered that numerous details regarding the exact mechanisms of processing and saving information in the human brain have not yet been fully comprehended and are continuously investigated by neuroscientists (F. Rattay, personal communication, August 20, 2023). Therefore, it is impossible to model them in artificial neural networks. Consequently, the comparison between human and artificial neural networks itself is most likely not feasible. Additionally, this comparison is not necessary to begin with, as the mechanisms of both artificial and human neural networks are excellent for their respective domains and applications since artificial neural networks are primarily designed for specific problem solving and not to model and understand the complex workings of human neural networks (F. Rattay, personal communication, June, 2023).
How reliable is ChatGPT and is it constantly evolving?
Naturally, various experts have also voiced numerous critical opinions related to researchers and primarily students relying heavily or solely on ChatGPT for text production, including the following (Tardy, 2023):
- Suboptimal genre knowledge as it is primarily a text generator
- Less active, deliberate, and creative decisions from writers
- Generation of a gap between producing knowledge (i.e., critical thinking) and disseminating knowledge (i.e., writing), leading to a decrease in critical thinking
- Copyright issues
While these issues are undeniably highly important – especially in the humanities, what they might have in common is another underlying issue: the dependence on the reliability and the transparency of the underlying data and updates of LLMs (cf. Chen et al., 2023; Hashana et al., 2023). Although we know that ChatGPT was trained on a variety of texts that are available online and continues to learn based on the questions users input, we do not know exactly which data it is and what type of selection procedure went into it. Furthermore, there are numerous ways to include filtering functions in neural networks, which makes it even less transparent for us users – especially since the vast majority of us will not invest hours of work to become LLM experts and fully comprehend every single function used in these models. Therefore, it may be problematic to view ChatGPT as a completely objective source of information.
Furthermore, a recent study by Chen et al. (2023) related to the data quality has posed the question of in how far crucial functionalities of ChatGPT change over time. The study investigated the two versions, GPT-3.5 and GPT-4, in March and June 2023 and tested their respective responses to a plethora of tasks, including sensitive questions, opinion questions, and knowledge-intensive questions. It found that the manner in which the AI answers these questions changes over time. For instance, while sensitive questions became less likely to be answered over time, the explanation for not answering was considerably shorter. Similarly, the accuracy rate of identifying composite and prime numbers decreased considerably for GPT-4 in June. Intriguingly, while GPT-4 demonstrated better results concerning questions that require either several sources or steps for the response (i.e., multi-hop tasks) in June than in March, GPT-3.5 actually performed worse in the same timeframe. These changes in performance between two versions of the same LLM and over such a short period of time suggest that these models should be evaluated continuously (Chen et al., 2023).
What does it all mean for us users?
I believe that as users, we can definitely enjoy working with ChatGPT while appreciating and maybe digging deeper into its incredibly complex underlying architecture. However, the constant evolution of these LLMs and underlying data set underlines the importance of taking an approach with ChatGPT that makes use of the model’s advantages but also acknowledges that we should not treat it as an inherently objective source of information and rely on it blindly.
Sophia Kaltenecker is a PhD student of English and American Studies and studies biomedical engineering at the TU Wien. Her research interests include ELF in the domains of business and natural sciences, genre and discourse analysis, functionalities of biomembranes, and electrical brain stimulation for treating aphasia.
References
Chen, L., Zaharia, M., Zou, J. (2023). How is ChatGPT’s behavior changing over time?. arXiv. https://doi.org/10.48550/arXiv.2307.09009
Hashana, A. M. J., Brundha, P., Ayoobkhan, M. U. A., Fazila, S. (2023). Deep learning in ChatGPT – A Survey. Proceedings of the 7th International Conference on Trends in Electronics and Informatics (ICOEI 2023), 1001-1005. https://doi.org/10.1109/ICOEI56765.2023.10125852
Kaplan-Marans, E., Khurgin, J. (2023). ChatGPT wrote this article. Urology. https://doi.org/10.1016/j.urology.2023.03.061
Kung, T. H., Cheatham, M., Medenilla, A., Sillos, C., De Leon, L., Elepaño, C., Madriaga, M., Aggabao, R., Diaz-Candido, G., Maningo, J., Tseng, V. (2023). Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digital Health, 2(2), Article e0000198. https://doi.org/10.1371/journal.pdig.0000198
Qadir, J. (2022). Engineering education in the era of ChatGPT: Promise and pitfalls of generative AI for education. TechRxiv. https://doi.org/10.36227/techrxiv.21789434.v1
Ray, P. P. (2023). ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 3, 121-154. https://doi.org/10.1016/j.iotcps.2023.04.003
Tardy, C. (2023, June 28-30). LSP in the era of ChatGPT [Conference presentation]. AELFE-LSPPC International Conference, Zaragoza, Spain.
Tucci, L. (2018, May). Artificial neuron. TechTarget. https://www.techtarget.com/searchcio/definition/artificial-neuron